
An intelligent Q&A system for vessel equipment faults based on large language models and retrieval augmented generation technology

-
摘要:目的
为了解决舰艇装备的故障诊断效率较低、难以与指挥员进行有效信息沟通等问题,提出一种采用自然语言交互的故障诊断方法。
方法首先,基于面向领域的设计理念,利用大语言模型和检索增强生成技术,构建一个舰艇装备故障智能问答系统;然后,提出一套文档预处理方法和综合检索策略,以优化系统性能;最后,设计一套综合评估方案对系统进行全面评估。
结果实验结果表明,相较于基础问答系统,优化后的智能问答系统仅需使用自然语言描述故障现象即可迅速定位故障原因和维修方案,显著提高了故障诊断效率,其ROUGE得分提高了2倍,BERTScore得分提高了约30%,专家评分提高了1.5倍,系统响应时间比传统人工检索方式减少了95%。
结论研究成果为海警舰艇在复杂任务环境下快速恢复装备性能提供了有力技术支撑。
Abstract:ObjectivesTo address the low efficiency in fault diagnosis for vessel equipment and the difficulty in effectively communicating with commanders, a solution is proposed. This solution employs natural language interaction to rapidly pinpoint the cause of faults and suggest maintenance plans.
MethodsFirstly, based on the domain-oriented design concept, an intelligent question answering system was constructed utilizing a Large Language Model and Retrieval Augmented Generation technology. Subsequently, a set of document preprocessing methods and comprehensive retrieval strategies were introduced to enhance system performance. Finally, a comprehensive evaluation scheme was devised to thoroughly assess the system.
ResultsExperimental results demonstrate that, by merely using natural language to describe the fault phenomenon, the system can quickly locate the cause of the fault and provide maintenance solutions, significantly improving the efficiency of fault diagnosis. Compared to basic question answering systems, the optimized question answering system has doubled its ROUGE score, achieved a nearly 30% increase in BERTScore, received a 1.5-fold increase in expert ratings, and a 95% reduction in system response time compared to traditional manual retrieval methods.
ConclusionsThis offers robust technical support for the rapid recovery of equipment performance on coast guard vessels in complex mission environments, effectively enhancing their combat effectiveness and mission execution capabilities.
-
0. 引 言
随着周边海上形势的日趋严峻,海警部队担负的维权执法任务逐渐繁重,而任务中的对抗烈度亦不断升级。根据近年来一线部队的实际任务情况,装备使用强度高与维护保养不及时之间的矛盾愈加凸显,所以突发性装备故障的风险也随之大幅上升。一旦发生装备故障,能否快速、准确地判明原因并予以排除,将直接关系到任务的成败。作为独立的作战平台,舰艇在执行任务期间一般远离岸基保障体系,也无法通过普通的通信手段来获得专家技术支持;舰艇上虽然存有大量的装备资料和维修手册等指导性文件,但临时查阅的效率较低,因此,亟需一种能够快速提高故障诊断效率的方法。
目前,关于舰船装备故障诊断方面的研究主要围绕优化故障诊断算法而展开:向波等[1]根据油液检测数据,提出了一种基于粗糙集(rough set,RS)与核极限学习机(kernel extreme learning machine,KELM)相结合的作战舰艇柴油机磨损故障诊断方法;任松涛[2]研究了基于数字信号处理(digital signal processor,DSP)的船舶航海仪器故障诊断方法;阮佳[3]设计了一种基于人工鱼群算法的船舶电子设备故障智能诊断方法。这些研究虽然都取得了有益的进展,但也存在一些问题:1)泛化能力差,以深度学习技术为例,其应用往往涉及获取信号、特征提取、训练模型、故障诊断等环节。由于不同装备的故障特征千差万别,因此针对某一装备而训练的模型无法用于其他装备。如果为每一套装备都训练专有的诊断模型,则需投入巨大的时间成本和经济成本。2)需依赖专业的检测设备和相关的领域知识,例如在信号获取阶段需要大量的传感器来采集振动、噪声、温度、压力等信号,且在信号数据预处理、特征提取、模型训练等阶段均需要丰富的领域知识作为支撑,这显然超出了基层官兵的知识范畴。3)任何诊断模型的训练都离不开大量的故障数据,而这在实船工作环境和实验室环境中均难以全面获取,因此,上述研究方法难以在基层部队落地。
随着以生成式预训练变换器(generative pre-trained transformer,GPT)[4]为代表的大语言模型(large language model,LLM)技术的飞速发展,为解决该问题提供了新的可能。大语言模型在通用领域展现了强大的语义理解和自然语言处理能力[5],而基于大语言模型+本地知识库的问答系统,无需复杂的信号特征提取和建模过程,即可有效融合大模型的推理能力和垂直领域的专家知识,通过自然语言交互的方式可以快速准确地解答垂直领域问题,同时可以随时更新和补充知识库内容,非常适合复杂系统的故障诊断和健康管理等任务,因此该技术逐渐应用于工业领域。然而,目前鲜有将大语言模型技术应用于海警舰艇装备故障诊断方面的研究成果,还存在很大的探索空间。
为此,本文拟在深入调研海警舰艇部队实际困难和任务需求的基础上,首先,基于Langchain-Chatchat[6]框架,利用大语言模型+本地知识库的方法,构建一个可离线部署的海警舰艇装备故障智能问答系统(intelligent Q&A system for equipment faults of China Coast Guard vessel,CCG-QA),从而高效检索装备文件并快速解答装备故障方面的问题;然后,以海警某型巡逻舰为例来构建一个舰艇装备知识库,并针对海警装备文件的特点,优化设计数据预处理模块、知识库选择模块和综合检索模块,以有效限制大模型“幻觉”,提升问答系统的问答精度;最后,以主动力柴油机为例设计测试问题集和实验评估流程,并使用基于召回率的自然语言处理评估指标ROUGE[7] (recall-oriented understudy for gisting evaluation)、评估自然语言生成(NLG)输出质量的评估指标BERTScore[8](bidirectional encoder representation from transformers score)及专家评分这3个指标来全面考察系统性能,用以为舰员快速准确地排除故障提供有力帮助。
1. 研究背景
1.1 知识问答系统的发展
人类对知识问答系统的研究可以追溯到20世纪50年代的图灵测试[9],闫悦等[10]全面回顾了问答系统的发展历程,文森等[11]研究了基于大语言模型的问答技术。根据技术特点的不同,可以将知识问答系统的发展分为5个阶段:1)基于结构化数据库的专用问答系统,其实现了利用自然语言回答特定领域问题的初步突破,但准备高质量的结构化数据需要耗费大量的人工和时间成本。2)基于大规模文档集的通用问答系统,其数据来源于网络文档,数据质量难以保证,所以问答的准确率较低。3)基于问题答案对的问答系统,分为基于常问问题的问答系统(frequently asked questions,FAQ)[12]和基于社区问答的问答系统(community question answering,CQA)[13],这类系统已在工业界得以应用,但存在获取问答对的成本较高和鲁棒性较低的问题。4)基于知识图谱的问答系统[14],其需要首先根据领域知识来构建知识图谱,然后才能提取准确、详细的答案,所以问答质量有了很大的提升;但是,人工构建知识图谱将过于依赖专家知识且成本高昂,而使用人工智能技术自动构建知识图谱仍存在很大的技术难度,所以该方法也存在一定的局限性。5)基于大语言模型的问答系统,虽然以ChatGPT为代表的大语言模型能够在通用领域很好地回答用户问题,但是将大语言模型直接应用于特定领域的问答任务时,其表现却不尽如人意,其在某些没有训练过的问题上将出现编造答案的现象,即所谓的“幻觉”。为了解决这一问题,目前有2个主要的研究方向:参数微调[15]和检索增强生成(retrieval-augmented generation,RAG)[16]。由于现有大语言模型的参数量巨大,参数微调对GPU算力的要求很高,其高昂的计算成本并不适用于普通用户,因此,不需要微调大语言模型的RAG技术应运而生,并逐渐成为了知识问答领域的研究热点。
1.2 检索增强生成(RAG)技术
为解决预训练大语言模型在垂直领域问题中的回答精度较低和易产生幻觉的问题,Meta AI于2020年提出了RAG技术,其核心思想是在回答问题之前,先将与用户问题紧密相关的资料提供给大模型,然后再结合已知资料进行推理,进而生成相应的问题答案。RAG系统架构包括参数记忆(Parametric)与非参数记忆(Non-Parametric)两部分,具体工作流程如下:当用户提出问题(query)时,首先,将问题输入非参数记忆部分,通过查询编码器(query encoder)转化为问题向量;然后,采用最大内积搜索(maximum inner product search,MIPS)方式从文档向量索引中查找最相似的前K个文档;最后,将这K个文档和问题合并输入参数记忆部分,由参数记忆部分经过推理而生成相应的答案。
采用RAG技术的问答系统引入了专业领域知识作为辅助,其相较于直接使用大语言模型进行问答的优势为:1)不需要对大模型进行再训练和参数微调,大幅降低了时间和算力成本;2)知识文档可以随时更新,具备良好的扩展性;3)可以有效抑制大模型的“幻觉”现象;4)可以对答案来源进行回溯,方便查证比对;5)可以实现本地部署,私有知识文件不需要上传网络,有效避免了私有数据泄露。
1.3 国产开源大模型
随着ChatGPT 的爆火,国内研究者也加快了在该领域的研发速度,先后推出了多款开源中文大语言模型,例如清华大学提出的 ChatGLM[17]、复旦大学提出的MOSS、阿里巴巴提出的通义千问等,其中ChatGLM3-6B是ChatGLM系列的新一代产品,具有62亿参数规模,并针对中文问答和对话进行了优化,是为数不多的可在消费级显卡上部署的国产大模型之一。本文在构建CCG-QA系统时,考虑到海警舰艇上硬件设施的实际情况,以及小型化、离线化等方面的要求,经过反复实验对比,最终选定了ChatGLM3-6B作为基座模型。
2. 海警舰艇装备故障智能问答系统(CCG-QA)的设计实现
CCG-QA系统采用面向领域的设计理念,其构建工作主要分2个阶段:第一阶段是利用Langchain-Chatchat[6]框架搭建一个基于基础RAG技术的问答系统(下文简称为“基础问答系统”);第二阶段是对文件导入、处理和检索等环节进行优化设计。
2.1 系统架构
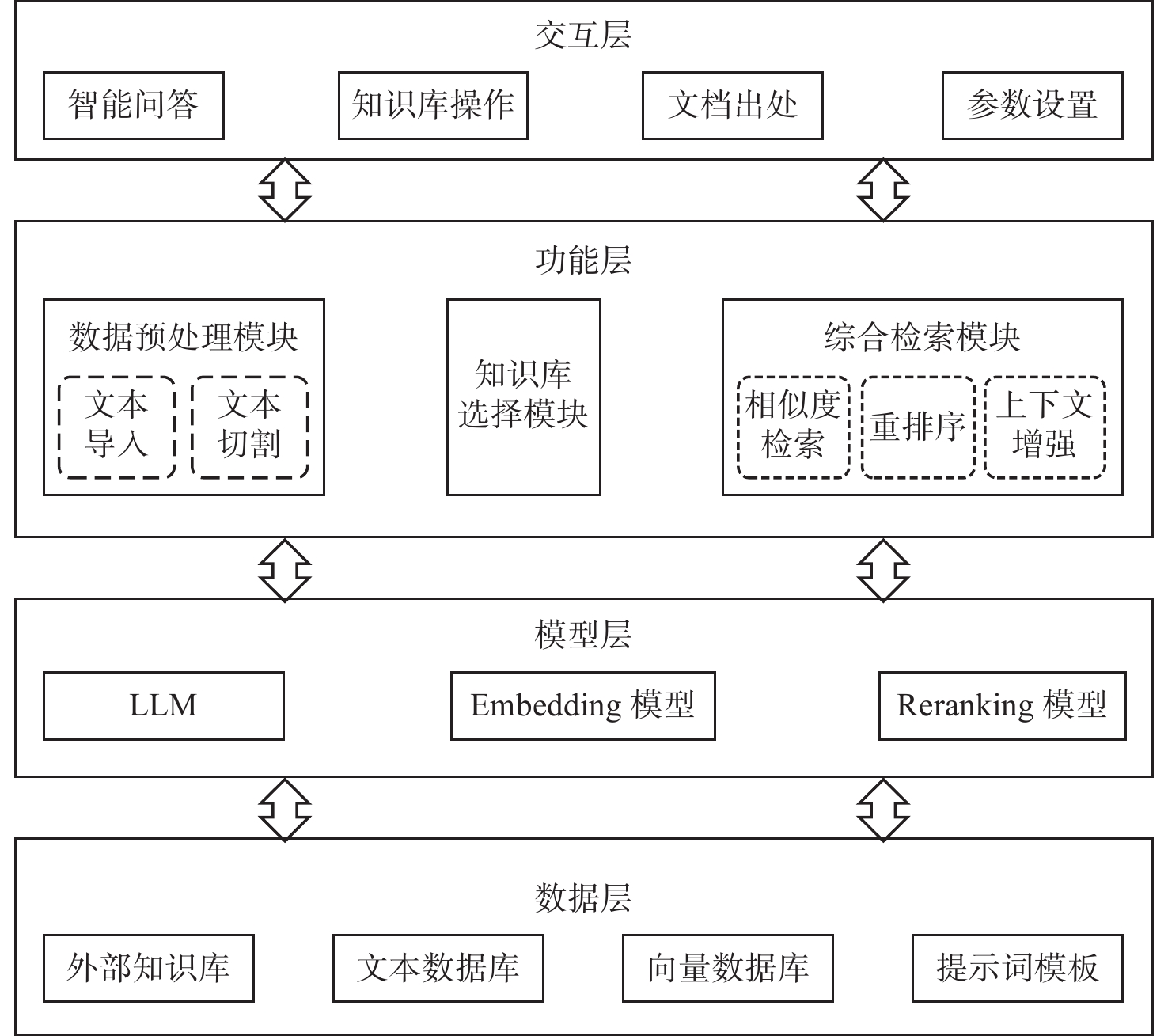
CCG-QA系统架构分为4层(如图1所示),每层的组成和功能描述如下:
![]() 图 1 海警舰艇装备故障智能问答系统的架构图Figure 1. Architecture diagram of intelligent question and answer system for equipment faults of coast guard vessels
图 1 海警舰艇装备故障智能问答系统的架构图Figure 1. Architecture diagram of intelligent question and answer system for equipment faults of coast guard vessels1)数据层。
数据层的主要功能是存储问答系统的基础数据,包含:(1)外部知识库,负责存储整理好的装备文件;(2)文本数据库,用于存储切割好的短文本并建立索引;(3)向量数据库,用于存储短文本的向量化数据,方便问答系统进行向量检索;(4)提示词模板:用于对大模型进行角色定位、提示思考、限定输出格式等,可根据实际需要设置多个模板。
2)模型层。
模型层包含本地部署的大语言模型(ChatGLM3-6B)、Embedding模型和重排序模型。BAAI general embedding(BGE)是由北京智源人工智能研究院(Beijing academy of artificial intelligence,BAAI)开发的开源通用向量模型,该模型专为各类信息检索及大模型检索增强应用而设计,支持多语言、多场景的应用需求,一经发布便在MTEB和C-MTEB基准测试中取得了第1名。目前BGE模型有多个版本,便于通过Langchain或Huggingface Transformers等工具进行调用,经过实验对比之后,本文选择了BGE系列的bge-large-zh-v1.5和bge-reranker-large分别作为智能问答系统的Embedding模型和重排序模型。
3)功能层。
这是确保问答系统性能的核心部分,主要包含3个功能模块:(1)数据预处理模块,用于将外部文档库的原始文件导入系统,并切割成多个短文本;(2)知识库选择模块,负责对用户问题进行意图识别,为下一步的检索确定目标向量库;(3)综合检索模块,用于为大模型提供准确的上下文信息。
4)交互层。
这是用户和系统交互的窗口,包含4个模块:(1)智能问答模块,用于实现系统问答主功能;(2)知识库操作模块,可以完成知识库更新和删减等操作;(3)参数设置模块,可以实现对知识匹配阈值、返回文档数量等超参数的设置,也可以对提示词模板进行选择;(4)文档出处模块,可以实现对文档来源的追溯和比对。
2.2 信息流程
CCG-QA系统的信息流程主要分为构建向量数据库和实现知识问答两部分:
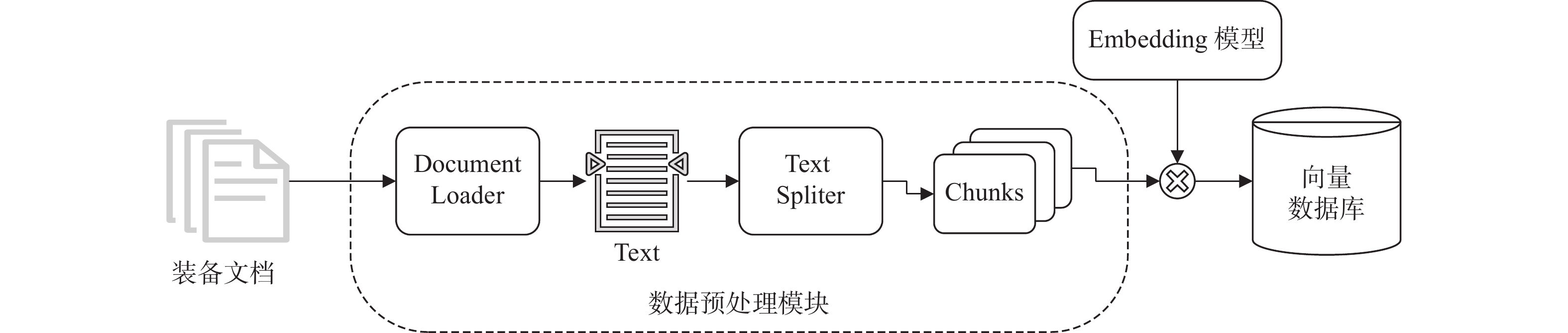
1)构建向量数据库的信息流程如图2所示:首先,利用文档导入器(document loader)将外部知识库文档导入问答系统,并根据需要使用文本分割器(text spliter)分割成合理大小的文本块(chunks);然后,利用embedding模型将文本块向量化,进而构建FAISS[18]向量库。
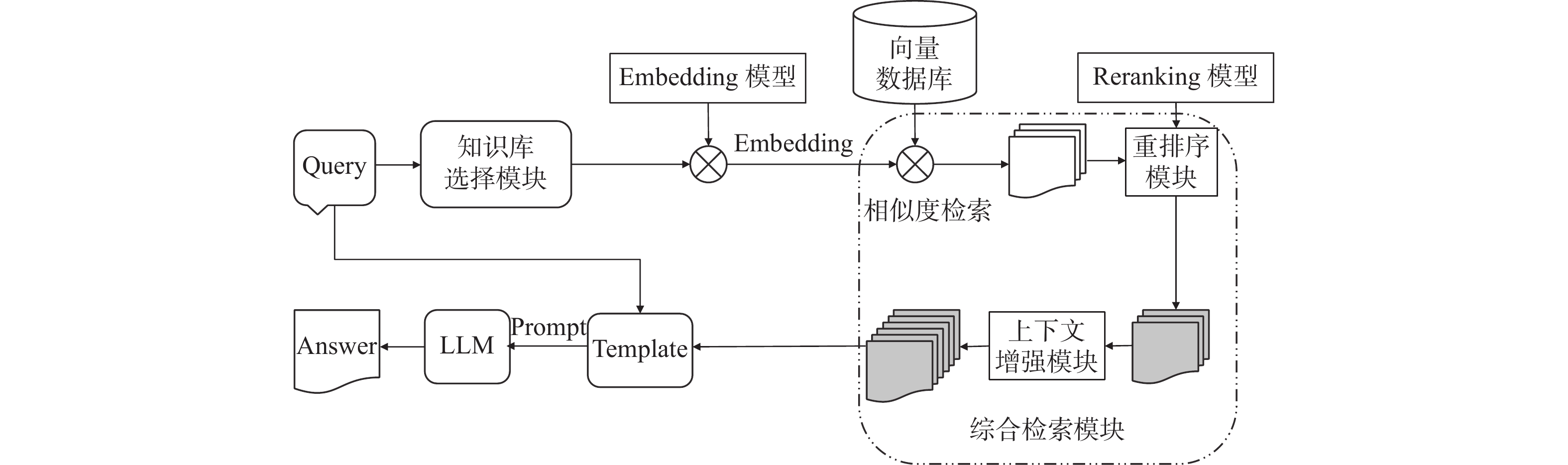
2) 实现知识问答的信息流程如图3所示:首先,知识库选择模块对用户问题进行意图识别,并根据识别结果选择对应的目标向量库,同时对用户问题进行向量化处理;其次,综合检索模块利用相似度检索技术从向量数据库中检索出与用户问题相关的多个文本块,并利用Reranking模型根据语义相关程度对其进行重新排序,获取排名靠前的K个文本块;然后,利用上下文增强技术对文本块的内容进行扩充;最后,将用户问题、扩充后的文本块嵌入Prompt提示词模板并提供给大模型,由大模型经推理之后给出问题答案。
2.3 数据结构
构建智能问答系统过程中所涉及的三类数据为:1)外部资料,主要包含电子版的装备完工文件、技术说明书、维修手册等,存储格式为PDF,DOC,DOCX等。2)内部文本块,当外部资料导入系统后,首先根据一定规则切割为短的文本块,然后将其存储为LangChain的一种抽象文档形式(dcoument),每一个文档块包含2个属性:page-content部分是文档的文本内容,而格式为字符串(str);元数据metadata则包含了文档的来源、标题、作者等其他辅助信息。3)向量数据,利用Embedding模型将文本块映射为向量数据,这些向量由64位浮点数组成的多维数组予以表示,可以被计算机直接处理。对于不同Embedding模型,向量的具体维度也有所不同,本文使用的Embedding模型是bge-large-zh-v1.5,因此其向量维度是1 024。
2.4 技术实现
2.4.1 硬件配置及部署环境
本文采用了消费级服务器进行相关部署,具体硬件配置、部署环境和程序语言选择如下:CPU为13th Gen Intel(R) Core(TM) i7-13650HX 2.60 GHz,GPU为NVIDIA GeForce RTX4060 Laptop,显存为8 GB,程序语言为Python(版本3.10.13),运算平台Cuda的版本为12.1。
2.4.2 基础问答系统构建流程
LangChain是由Harrison Chase于2022年10月发布的一个开源框架,用于开发由大语言模型驱动的应用程序。Langchain-Chatchat[6]是利用Langchain思想实现的基于本地知识库的问答应用,也是RAG技术的一种具体实现。本文采用Langchain-Chatchat框架构建了基础问答系统,其具体流程如下:1)建立外部知识库:由舰艇装备完工文件等电子文档组成;2)建立向量库:将外部知识库文档导入问答系统,并分割成多个文本块,再利用Embedding模型将文本块转换为向量后存入向量库;3)向量检索:对用户问题进行向量化处理,并利用向量检索技术获取与用户问题密切相关的文本块;4)生成答案:大语言模型根据用户问题、提示词和检索得到的文本块来生成问题答案。
2.4.3 构建外部知识库
海警舰艇拥有庞大的装备体系,大致分为通导、武备、动力、舰载机以及系泊设备五大类,共计两百余种,相关的装备文件主要分为3种:1)装备厂家提供的完工文件、使用说明、维修手册等,格式多为 PDF;2)舰艇官兵自行编写的典型故障汇编、维护保养手册等,格式多为 DOCX;3)领域专家的培训课件,格式多为PPTX ,由此可见,装备文件具备种类繁多、格式不一、质量参差不齐等特点。
为了确保智能问答系统的问答精度,本文从所收集的海警某型巡逻舰的近千份原始文档中仔细筛选了质量较好的600余份文档,并按照装备类型、功能模块等进行分类存储,完成了CCG-QA系统的知识库构建,具体组成如表1所示。
表 1 知识库文档统计Table 1. Knowledge base document statistics类别 数量/份 格式 使用说明书 161 PDF 维修手册 143 PDF 故障汇编 13 DOCX 培训教材 161 PPTX 维护保养细则 135 DOCX 2.4.4 数据预处理模块的设计
数据预处理模块需要将不同格式的文件(PDF,PPTX,DOCX等)通过相应的文档导入器(RapidOCRPDFLoader,UnstructuredFileLoader等)导入系统,并转换为统一格式后进行处理,从而确保系统可以高效管理和检索各类装备文件。由上文分析可知,装备厂家提供的说明书等文件大都为PDF格式,且存在2个突出的特点:1)存在大量的图片和图表内容;2)章节符号比较完备,各级标题用词简练,是对本章节内容的精准总结和概括。相关研究指出,LangChain中使用的PDF解析器存在无法准确识别段落和表格的边界及内部结构、无法识别内容的阅读顺序等诸多缺陷[19],因此,原文档中的结构化、半结构化数据在解析过程中将丢失结构信息,无法进行正确的语义表达。
为解决这一问题,本文对数据预处理模块的文档导入器和文本分割器进行了重新设计。首先,使用开源库pdfminer将PDF文档页面中内容解析为文本、图像、表格三种类型的分块;然后,分别使用pdfminer,pdf2image,pytesseract,pdfplumber等开源库将各种类型分块中的文字信息提取出来,并按一定顺序重新拼接成新的字符串,例如处理表格内容时,以“\n”符区分表格每一行,以“|”符区分每一个单元格的内容,同时消除原单元格内的所有不必要的换行符,即可将表格内容转换成为markdown格式的轻文本格式,并保留必要的结构化信息,从而便于大模型准确理解文档结构和语义;最后,灵活调整文本分割器的分割策略,优先选择以章节符号作为分割边界,既可保证各章节标题处于文本块的首部,还可最大限度地保证文本块的语义完整性。
2.4.5 知识库选择模块的设计
Cuconasu等[20]的研究成果表明,当提供给大语言模型的上下文中包含某些相似但与问题不相关的信息时,将为大模型带来极大的干扰。舰艇上一般存在多种结构或功能相似的装备,这类装备知识如果同时出现,很容易使大模型张冠李戴,严重影响问答精度。为此,本文将为每一套装备建立各自独立的向量库,并在检索阶段加入知识库选择模块,通过利用语义分析、实体识别等自然语言处理技术来精准捕捉用户的查询意图,通过索引机制和基于规则的选择算法来快速定位与用户意图最匹配的检索向量库,从而有效避免装备知识混淆,明显提高问答系统的精度和效率。
2.4.6 综合检索模块的设计
在构建基础问答系统的过程中,本文发现了向量检索环节存在2个严重影响文本召回率和问答精度的问题:1)向量检索返回的上下文信息不全,这是由于文档分割时存在一定的字符数限制,故难以保证分割后的文本块包含足够的上下文信息。2)最相关的文档块在返回文档序列中的排名靠后,究其原因,FAISS向量库使用的是相似度检索方法,其产生的结果具有一定的随机性,因此往往出现与问题最相关的文本块在相似度检索中得分较低、在返回文档序列中排名靠后的情况,很容易被大模型忽视,从而导致问答精度大幅降低。
为解决上述问题,本文通过引入重排序(reranking)[21]技术和上下文增强(context enrichment)[22]技术重新设计了检索环节,组成了综合检索模块,具体方法如下:在第一阶段相似度检索之后,重排序模型利用深度学习技术将检索到的文本和用户问题转换为高维空间的向量表示,然后通过余弦相似度等度量方法再次计算彼此之间的相似度得分,并据此对检索结果进行重新排序,从而将真正与问题相关的文本块排在前面。由于重排序模型采用了更加精细的语义匹配,能够准确评估文档与查询之间的相关性,故其检索结果更符合用户的需求和期望。同时,为了进一步提升检索结果的准确性和相关性,本文还采用了上下文增强技术:首先,获取排在前面的top_K个文本块的元数据(metadata),结合其中包含的位置、内容摘要等关键信息,通过算法找到一定数量的上下文分块;然后,将这些分块扩展至原文本块前后的相关句子,从而形成一个更大的上下文窗口;最后,按顺序合并这些上下文分块,得到一个更加丰富和完整的上下文信息,从而提高检索结果的准确性和相关性。
2.4.7 提示词模板的设计
提示词模板主要需考虑明确的角色定位、清晰明了的任务指令、限定参考的知识范围、明确超范围问题的处理方法等设计原则。经过反复测试对比,本文采用的提示词模板为:“你是一名船舶机电工程师,熟悉船舶机电设备的内部结构、工作原理和维护保养方法,并且拥有丰富的故障维修经验。用户会向你提问一些关于船舶机电设备方面的问题,请根据已知信息,简洁、专业的回答。如果无法从已知信息中找到答案,请说“根据已知信息无法回答该问题”,不得编造答案。问题:{用户输入};已知信息:{从知识库中检索到的信息}”。
2.4.8 大模型幻觉的限制机理
大模型“幻觉”是指在使用大模型回答它没有被明确训练过的内容时,可能生成虚假或错误的信息,这是目前大模型应用中面临的主要挑战之一。为了充分限制大模型的幻觉,提升系统的问答精度,本文主要采用了示词工程和检索增强生成这2项技术,其基本原理是:1)明确角色定位,将模型角色定位为“船舶机电工程师”,帮助大模型更好地理解专业术语和上下文,从而生成更符合领域需求的回答;2)强调准确性,通过提示词“根据已知信息,简洁、专业的回答”约束大模型只能基于检索到的信息生成回答,防止其依赖预训练知识中的潜在错误或过时信息,同时避免大模型生成冗长或不相关的信息;3)明确约束条件,通过提示词“如果无法从已知信息中找到答案”,防止模型生成虚假或不确定的内容,提升系统的可信度;4)提供准确可靠的参考信息,通过完善知识库结构、优化综合检索模块设计等方法为大模型提供高质量的参考信息,进一步保证大模型生成答案的准确性和实用性。
3. 实验评估
3.1 测试问题集
主动力柴油机是舰艇动力系统的核心装备,其系统分支繁多、结构复杂,故障类别也最具代表性,因此,本节将以舰艇主动力柴油机为例,参考技术说明书、使用说明书、维修手册等相关资料,结合装备的实际使用经验来设计一套测试问题集。测试集共50道题,包含了基本参数、结构原理、操作使用等常规内容,同时涵盖了供油系统、进排气系统、配气机构、润滑系统、控制系统、冷却系统、曲柄连杆机构故障等七大类常见故障中的全部30余个知识点。
3.2 评估指标
3.2.3 专家评分
专家评分法是一种传统的评分方法,通过匿名方式征询有关专家的意见,然后对专家意见进行统计、处理、分析和归纳,其特点是操作简便、直观性强。本次实验邀请了由多名经验丰富的舰艇装备干部、专业骨干组成的3个专家组,分别对基础问答系统和CCG-QA系统的问答结果进行匿名打分,然后根据难度权值进行加权计算后得出最终得分,从而重点考察问答系统答案的专业性和实用性。
3.3 实验过程及结果展示
3.3.1 实验过程
1)实验准备。首先,依据专家经验将测试题按照难度层次划分为难、中、易三类,并为每一类赋予合理的权值,以确保测试结果的均衡性;然后,安装开源python库rouge-chinese和bert-score,用于编写该实验的测评程序。
2)问答实验。将测试集的50道题逐一输入基础问答系统和CCG-QA系统,收集2个系统输出的答案,并记录系统反应时间。
3)测评打分。首先,将2个系统输出的答案和对应的参考答案输入测评程序,获取两者在ROUGE和BERTScore相关指标上的测试得分;然后,将2个系统输出的答案分别与对应的测试问题组成问答对,以匿名形式发给3组舰艇专家进行主观打分。
4)数据处理。收集整理测评结果,将2个系统在每个指标上的得分进行归一化处理,进而计算加权平均值。
5)对比分析。根据实验数据,对比分析基础问答系统和CCG-QA系统在各项指标上的性能差异。
3.3.2 实例展示
CCG-QA系统的实际问答案例如表2所示,从输出的答案可以看出,智能问答系统的回答既包含来自本地知识库的知识点,还融入了大模型自身的延伸推理,很好地实现了大模型与本地知识库的融合。
表 2 实际问答示例Table 2. Actual Q&A examples问题 CCG-QA系统答案 参考答案 主机滑油温度偏高,请分析原因和应对措施? 主机滑油温度偏高的原因可能有:1)恒温阀损坏:恒温阀负责控制滑油温度,如果损坏,可能导致滑油温度升高;2)冷却水流量不足:冷却水是用来降低发动机温度的重要介质,如果流量不足,可能导致发动机过热;3)发动机有异常发热:发动机正常运行时会产生一定的热量,如果存在异常发热,可能导致滑油温度升高。
应对措施:1)检查恒温阀:如果损坏,及时更换相关零部件;2)检查冷却水系统:确认冷却水流量是否充足,如果不足,需要增加冷却水流量;3)检查发动机:确认是否存在异常发热现象,如果有,需要检查主要动力传递件的受热情况,并采取相应的措施进行修复。主机滑油温度过高的原因和相应的处理措施有:1)恒温阀损坏,应更换有毛病的“感温”元件;2)冷却水流量不足,应检查冷却水系统;3)发动机有异常发热,应检查主要动力传递件的受热情况。 3.3.3 专家评分结果
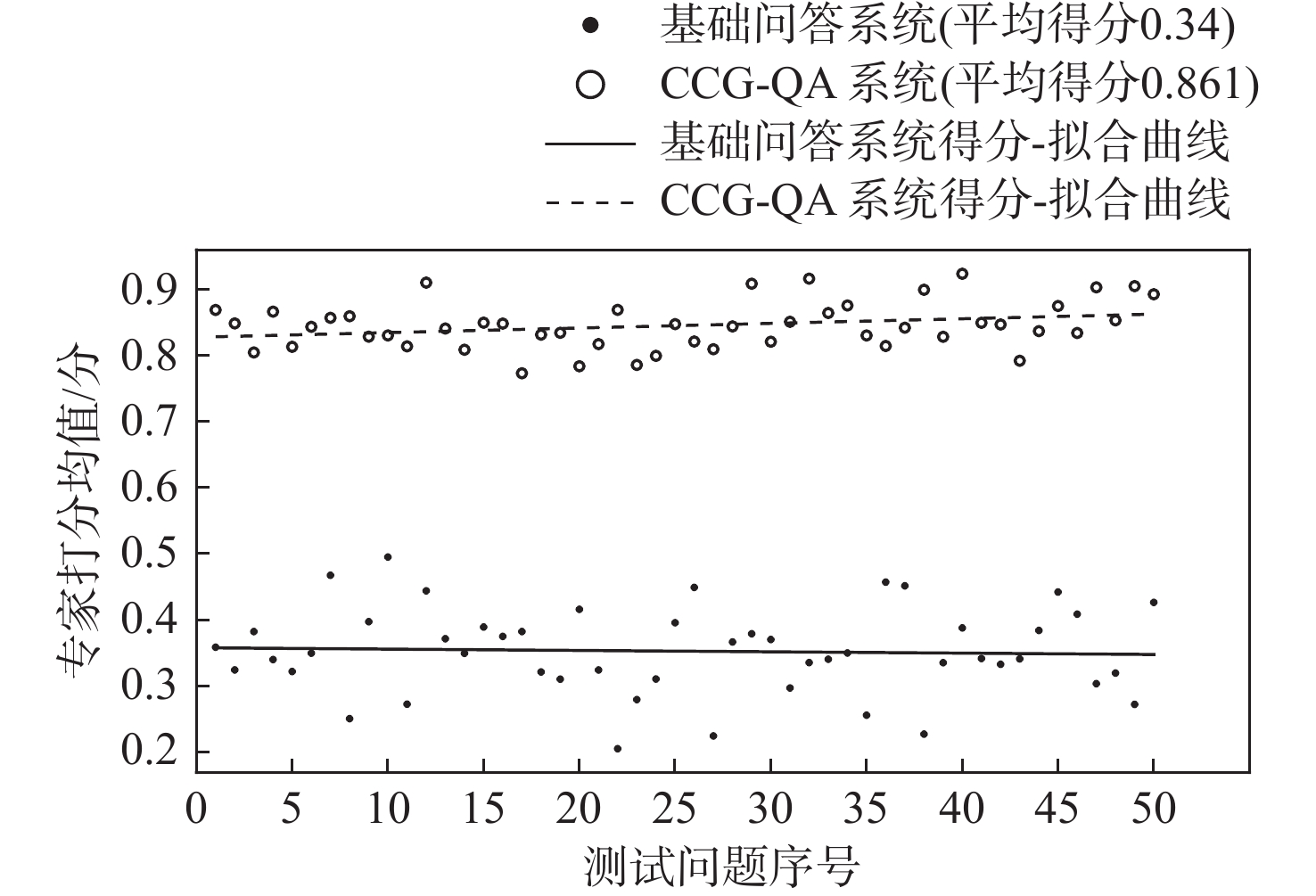
专家评分结果如图4所示,横轴为测试问题序号,竖轴为3组专家对每一个问题打分的平均值,其中空心点表示CCG-QA系统的得分,实心点表示未经优化的基础问答系统的得分。从图4可以直观地看出:相较于基础问答系统,CCG-QA系统的平均得分提高了约150%;从分值的整体分布而言,CCG-QA系统在整个测试集的得分范围比较集中,而基础问答系统的得分范围则明显比较分散,充分验证了本文所提方法的有效性和稳定性。
3.3.4 综合性能评估
优化前后的问答系统在各项指标上的综合测试结果如表3所示,可以看出,优化后问答系统的各项指标均出现了大幅提升,再次验证了本文方法的有效性;在专家评分环节获得了0.861分,表现特别优异,即基本具备了指导实际工作的能力。
表 3 性能评估结果Table 3. Performance evaluation results问答系统 ROUGE-1 ROUGE-2 ROUGE-l BERTScore 专家评分 Precision Recall F1 基础问答系统 0.276 0.188 0.223 0.697 0.687 0.693 0.340 CCG-QA 0.771 0.609 0.703 0.865 0.913 0.887 0.861 3.2.1. ROUGE
ROUGE是一种衡量文本摘要质量的评估方法,用于对比模型生成的摘要与人工编写的参考摘要之间的相似度。ROUGE指标包括ROUGE-N,ROUGE-L等多个子指标,通过计算连续n个词组合(n-gram)的重叠度来评估文本摘要的质量,在自然语言处理领域的应用较为广泛。
3.2.2. BERTScore
BERTScore是一种基于BERT模型的评估指标,用于衡量两段文本之间的语义相似度,其基本理念是将2个句子分别输入到预先训练好的BERT模型中,获取句子的语义向量,然后比较这些向量的余弦相似度。这种方法利用了BERT模型的上下文感知能力,能够捕捉更细腻的语义相似性、更好地理解文本的语义内容,即使2个句子不包含相同的词语也能评估出两者之间的相似性,所以在自然语言处理任务中可以提供更全面的文本生成质量评估。
4. 结 论
本文创新性地将大语言模型与检索增强生成技术相结合,成功构建了适用于海警舰艇装备故障诊断的智能问答系统,显著提高了诊断效率,为舰艇装备保障提供了新的技术手段。该系统对硬件配置要求较低,可在不同舰型上离线部署,且操作简单、易于掌握。虽然因受到数据质量、检索策略、量化版大模型推理能力等因素的限制,但已初步验证了利用大语言模型技术来解决舰艇部队装备维修问题的可行性,结论如下:
1)从检索速度而言,通过智能问答系统只需十几秒即可获得准确答案,显著提高了检索效率,比传统人工检索方式节约了95%以上的时间成本。
2)从准确度而言,相较于基础问答系统,CCG-QA系统的ROUGE得分提高了2倍,BERTScore得分提高了约30%,专家评分提高了1.5倍,得到了舰艇专家的充分认可。
3)为了有效限制大模型的幻觉,本文综合采用了提示词工程与检索增强生成两项先进技术。通过精心设计prompt提示词,为大模型明确其角色定位、指令要求和任务背景,引导其更加精准的理解和处理问题;通过引入RAG技术为大模型提供丰富的领域知识,进一步增强其问答的准确性和针对性。实验结果表明,本文方法不仅充分发挥了大模型在理解和推理方面的优势,还显著提升了输出文本的质量,有效减少了幻觉现象的发生,从而确保了问答系统的可靠性和实用性。
虽然该智能问答系统具备了帮助舰艇官兵提高故障诊断效率和装备维修水平的能力,但仍存在有待改进之处:
1)不具备语音交互功能,未来计划引入语音交互模块,利用语音编码/译码技术,实现系统与用户的语音交互,提升系统的智能化水平与便捷性。
2)由于在知识检索阶段采用了单跳检索,面对复杂问题时易导致无法全面获取相关知识,未来计划采用层级索引、递归检索、自适应检索[23]等技术进一步优化知识获取能力。
3)由于量化版大模型的推理能力有限,未来将尝试采用查询转换、复杂问题分解、思维链[24]等技术加以改进。
4)无法正确识别常见的零件图、电路图、系统流程图等,未来将考虑利用多模态技术[25]加以改进。
随着大模型技术的持续发展,未来可以进一步提升海警舰艇装备故障诊断智能问答系统的实际效果,并应用于辅助制订舰艇损管方案、应急处置预案、操演手册等文本生成类任务中。
-
![]()
图 1 海警舰艇装备故障智能问答系统的架构图
Figure 1. Architecture diagram of intelligent question and answer system for equipment faults of coast guard vessels
表 1 知识库文档统计
Table 1 Knowledge base document statistics
类别 数量/份 格式 使用说明书 161 PDF 维修手册 143 PDF 故障汇编 13 DOCX 培训教材 161 PPTX 维护保养细则 135 DOCX  下载: 导出CSV
下载: 导出CSV
表 2 实际问答示例
Table 2 Actual Q&A examples
问题 CCG-QA系统答案 参考答案 主机滑油温度偏高,请分析原因和应对措施? 主机滑油温度偏高的原因可能有:1)恒温阀损坏:恒温阀负责控制滑油温度,如果损坏,可能导致滑油温度升高;2)冷却水流量不足:冷却水是用来降低发动机温度的重要介质,如果流量不足,可能导致发动机过热;3)发动机有异常发热:发动机正常运行时会产生一定的热量,如果存在异常发热,可能导致滑油温度升高。
应对措施:1)检查恒温阀:如果损坏,及时更换相关零部件;2)检查冷却水系统:确认冷却水流量是否充足,如果不足,需要增加冷却水流量;3)检查发动机:确认是否存在异常发热现象,如果有,需要检查主要动力传递件的受热情况,并采取相应的措施进行修复。主机滑油温度过高的原因和相应的处理措施有:1)恒温阀损坏,应更换有毛病的“感温”元件;2)冷却水流量不足,应检查冷却水系统;3)发动机有异常发热,应检查主要动力传递件的受热情况。
下载: 导出CSV
表 3 性能评估结果
Table 3 Performance evaluation results
问答系统 ROUGE-1 ROUGE-2 ROUGE-l BERTScore 专家评分 Precision Recall F1 基础问答系统 0.276 0.188 0.223 0.697 0.687 0.693 0.340 CCG-QA 0.771 0.609 0.703 0.865 0.913 0.887 0.861
下载: 导出CSV
-
[1] 向波, 甘旭升, 韩宝安, 等. 作战舰艇柴油机磨损故障的RS-KELM诊断[J]. 火力与指挥控制, 2022, 47(7): 72–77. doi: 10.3969/j.issn.1002-0640.2022.07.013 XIANG B, GAN X S, HAN B A, et al. Study on RS-KELM diagnosis of wear fault for warship diesel engine[J]. Fire Control & Command Control, 2022, 47(7): 72–77 (in Chinese). doi: 10.3969/j.issn.1002-0640.2022.07.013
[2] 任松涛. 基于DSP的船舶航海仪器故障诊断[J]. 舰船科学技术, 2023, 45(24): 196–199. doi: 10.3404/j.issn.1672-7649.2023.24.037 REN S T. Fault diagnosis of marine instruments based on DSP[J]. Ship Science and Technology, 2023, 45(24): 196–199 (in Chinese). doi: 10.3404/j.issn.1672-7649.2023.24.037
[3] 阮佳. 基于人工鱼群算法的船舶电子设备故障智能诊断方法[J]. 舰船科学技术, 2023, 45(24): 188–191. doi: 10.3404/j.issn.1672-7649.2023.24.035 RUAN J. Intelligent fault diagnosis method of ship electronic equipment based on artificial fish swarm algorithm[J]. Ship Science and Technology, 2023, 45(24): 188–191 (in Chinese). doi: 10.3404/j.issn.1672-7649.2023.24.035
[4] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[J]. 2018. (查阅网上资料, 未找到本条文献刊名, 卷期和页码信息, 请确认)
[5] 柯沛, 雷文强, 黄民烈. 以ChatGPT为代表的大型语言模型研究进展[J]. 中国科学基金, 2023, 37(5): 714–723. doi: 10.16262/j.cnki.1000-8217.20230922.001 KE P, LEI W Q, HUANG M L. Research progress of large language models represented by ChatGPT[J]. Bulletin of National Natural Science Foundation of China, 2023, 37(5): 714–723 (in Chinese). doi: 10.16262/j.cnki.1000-8217.20230922.001
[6] LIU Q, SONG J K, HUANG Z G, et al. Langchain-Chatchat[DB/OL]. (2024). https://github.com/chatchat-space/Langchain-Chatchat. (查阅网上资料,未找到本条文献引用日期信息,请确认)
[7] LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]//Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, 2004: 74−81.
[8] ZHANG T Y, KISHORE V, WU F, et al. BERT Score: evaluating text generation with BERT[C]//International Conference on Learning Representations. 2020. (查阅网上资料, 未找到本条文献出版信息, 请确认)
[9] TURING A M. Computing machinery and intelligence[J]. Mind, 1950, 49: 433–460. doi: 10.1128/IAI.69.3.1739-1746.2001
[10] 闫悦, 郭晓然, 王铁君, 等. 问答系统研究综述[J]. 计算机系统应用, 2023, 32(8): 1–18. doi: 10.15888/j.cnki.csa.009208 YAN Y, GUO X R, WANG T J, et al. Survey on question answering system research[J]. Computer Systems & Applications, 2023, 32(8): 1–18 (in Chinese). doi: 10.15888/j.cnki.csa.009208
[11] 文森, 钱力, 胡懋地, 等. 基于大语言模型的问答技术研究进展综述[J]. 数据分析与知识发现, 2024, 8(6): 16–29. doi: 10.11925/infotech.2096-3467.2023.0839 WEN S, QIAN L, HU M D, et al. Review of research progress on question-answering techniques based on large language models[J]. Data Analysis and Knowledge Discovery, 2024, 8(6): 16–29 (in Chinese). doi: 10.11925/infotech.2096-3467.2023.0839
[12] SAKATA W, SHIBATA T, TANAKA R, et al. FAQ retrieval using query-question similarity and BERT-based query-answer relevance[C]//Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Paris France: Association for Computing Machinery, 2019: 1113−1116. doi: 10.1145/3331184.3331326.
[13] PATRA B. A survey of community question answering[J]. arXiv preprint arXiv: 1705.04009, 2017. doi: 10.48550/arXiv.1705.04009. (查阅网上资料,不确定本文献类型是否正确,请确认)
[14] 王智悦, 于清, 王楠, 等. 基于知识图谱的智能问答研究综述[J]. 计算机工程与应用, 2020, 56(23): 1–11. doi: 10.3778/j.issn.1002-8331.2004-0370 WANG Z Y, YU Q, WANG N, et al. Survey of intelligent question answering research based on knowledge graph[J]. Computer Engineering and Applications, 2020, 56(23): 1–11 (in Chinese). doi: 10.3778/j.issn.1002-8331.2004-0370
[15] DETTMERS T, PAGNONI A, HOLTZMAN A, et al. QLoRA: efficient finetuning of quantized LLMs[C]//Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans LA USA: Curran Associates Inc. , 2024: 10088−10115.
[16] LEWIS P, PEREZ E, PIKTUS A, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver BC Canada: Curran Associates Inc. , 2020: 9459-9474. doi: 10.48550/arXiv.2005.11401.
[17] ZENG A H, LIU X, DU Z X, et al. GLM-130B: an open bilingual pre-trained model[EB/OL]. (2022-10-05). https://arxiv.org/abs/2210.02414. (查阅网上资料,未找到本条文献引用日期信息,请确认)
[18] DOUZE, M, GUZHVA A, DENG C Q, et al. The Faiss library[EB/OL]. (2024-01-16). https://arxiv.org/abs/2401.08281. (查阅网上资料,未找到本条文献引用日期信息,请确认)
[19] LIN D M. Revolutionizing retrieval-augmented generation with enhanced PDF structure recognition[J]. arXiv preprint arXiv: 2401.12599, 2024. doi: 10.48550/arXiv.2401.12599. (查阅网上资料,不确定本文献类型是否正确,请确认)
[20] CUCONASU F, TRAPPOLINI G, SICILIANO F, et al. The power of noise: redefining retrieval for RAG systems[C]//Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. Washington DC USA: Association for Computing Machinery, 2024: 719-729.
[21] GAO Y F, XIONG Y, GAO X Y, et al. Retrieval-augmented generation for large language models: a survey[Z]. arXiv preprint arXiv: 2312.10997, 2023. doi: 10.48550/arXiv.2312.10997. (查阅网上资料,不确定本文献类型是否正确,请确认)
[22] ILIN I. Advanced rag techniques: an illustrated overview. 2023. https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6. (查阅网上资料,未找到本条文献信息,请确认)
[23] JEONG S, BAEK J, CHO S, et al. Adaptive-RAG: learning to adapt retrieval-augmented large language models through question complexity[C]//Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Mexico City: Association for Computational Linguistics, 2024: 7036−7050. doi: 10.18653/v1/2024.naacl-long.389.
[24] WEI J, WANG X Z, SCHUURMANS D, et al. Chain of-thought prompting elicits reasoning in large language models[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans LA USA: Curran Associates Inc. , 2022: 24824−24837.
[25] ZHAO R C, CHEN H L, WANG W S, et al. Retrieving multimodal information for augmented generation: a survey[C]//Findings of the Association for Computational Linguistics: EMNLP 2023. Singapore: Association for Computational Linguistics, 2023: 4736−4756. doi: 10.18653/v1/2023.findings-emnlp.314.
计量
- 文章访问数: 227
- HTML全文浏览量: 150
- PDF下载量: 26
